Case Study: Podscribr
Breaking down the hows and whys of development of Podscribr.com
Podscribr is the monetization engine for solo and duo podcasters: turn long-form audio into monetized blog posts and social content in minutes.
Overview
Role - Fullstack developer, product designer
Problem - Podcasters spend their time creating podcast content and don’t have the interest or time available to create marketing for their content. 10 hours podcast production in => 1 hour podcast content out.
Solution - Designed a tool to transcribe long-form audio, extract keywords from the audio, and write marketing content for podcasters.
Tech Stack
- Supabase database and user authentication
- Python
- FastAPI backend API framework
- PyDub audio processing
- Whisper speech to text model
- Docker containerized application for production deployment
- Google Cloud cloud VM provider
- OpenAi transcription and content generation
- RabbitMQ message broker
- Celery workers for message queue consumption
- Next.js frontend framework
- Vercel serverless platform
- Tanstack Form React forms library
- MDX Markdown for React
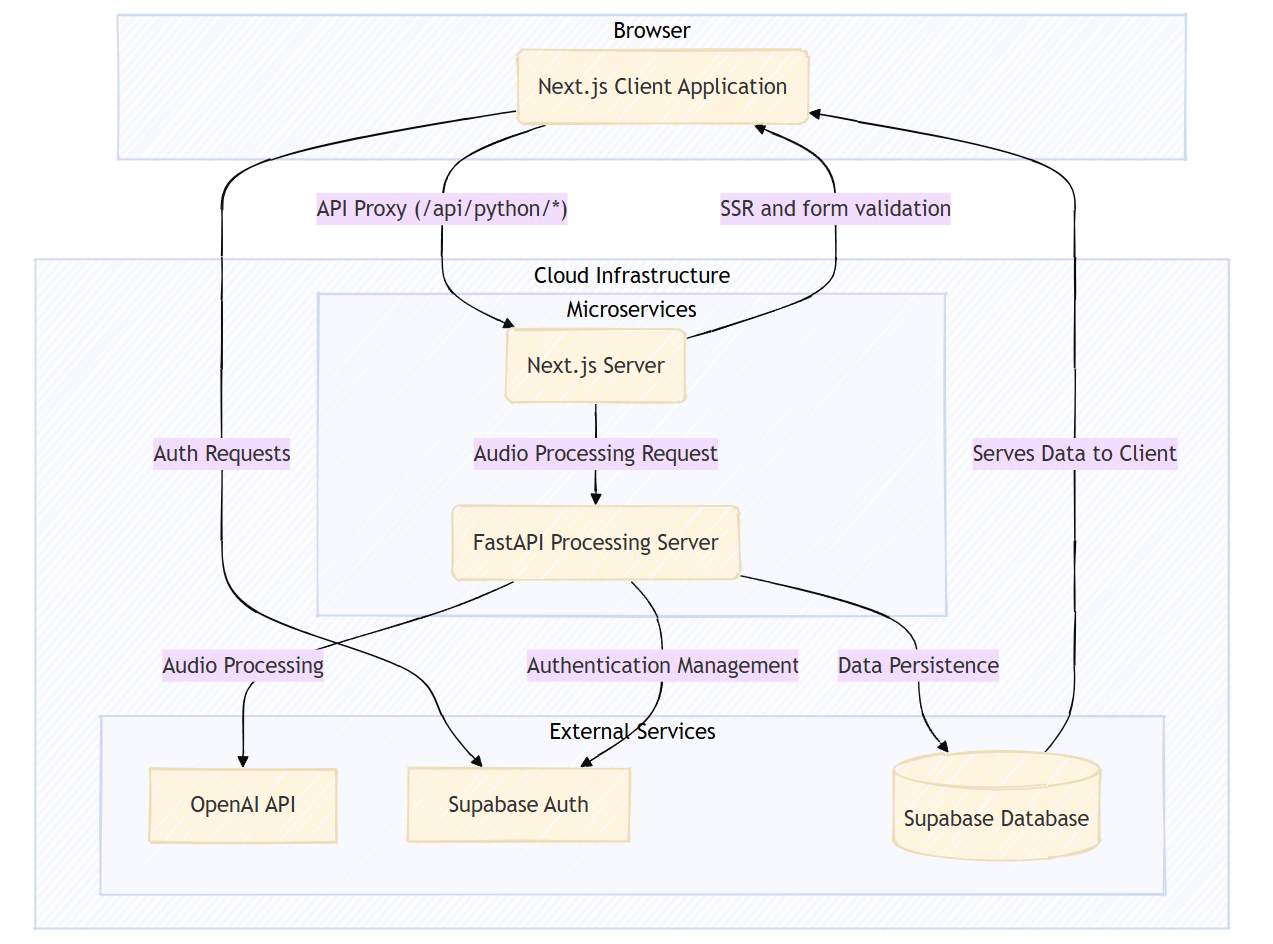 Podscribr.com architecture overview
Podscribr.com architecture overview
Motivation
- I had my own podcast from December 2021 - April 2022 and learned just how much work goes into creating an hour of entertaining, quality content. 10 hours production in => 1 hour content out
- I put it down because I left the gaming community the podcast was based in, but I always remembered how much work it was to make, and how much marketing work I had to do even after the audio was created: show notes, audio upload, social media posts, etc.
- Collecting brands and products mentioned in audio after editing the audio and ensuring everything got included in the show notes took several hours per episode. Podscribr is optimized around affiliate marketing by pulling out keywords and products mentioned in the transcript.
- I have been working with AI for online content generation for my personal blog and Boring Security posts, and with some conversations with some podcaster friends, realized I could create an application to automate the marketing content creation for podcasts.
- There are plenty of transcription tools available but the transcript by itself isn’t useful - no one reads it. However, it would be excellent context for an LLM creating content about the audio.
- Podscribr can generate accurate show notes and social media text content in 10 minutes using engineered prompts for output format, tone, and style.
Features and Functionality
- Named entity extractor to identify brands, products, and other keywords mentioned throughout the podcast
- Human-sounding blog content for the podcast creator to host on their own website
- Data export of audio transcription and generated text content
- Dashboard for viewing content created from each audio file
- Rendered preview of the generated markdown content
- Long-form transcription and marketing content generation by providing a URL to an audio file
- To start the processing pipeline, users provide a URL to a valid audio file through a form
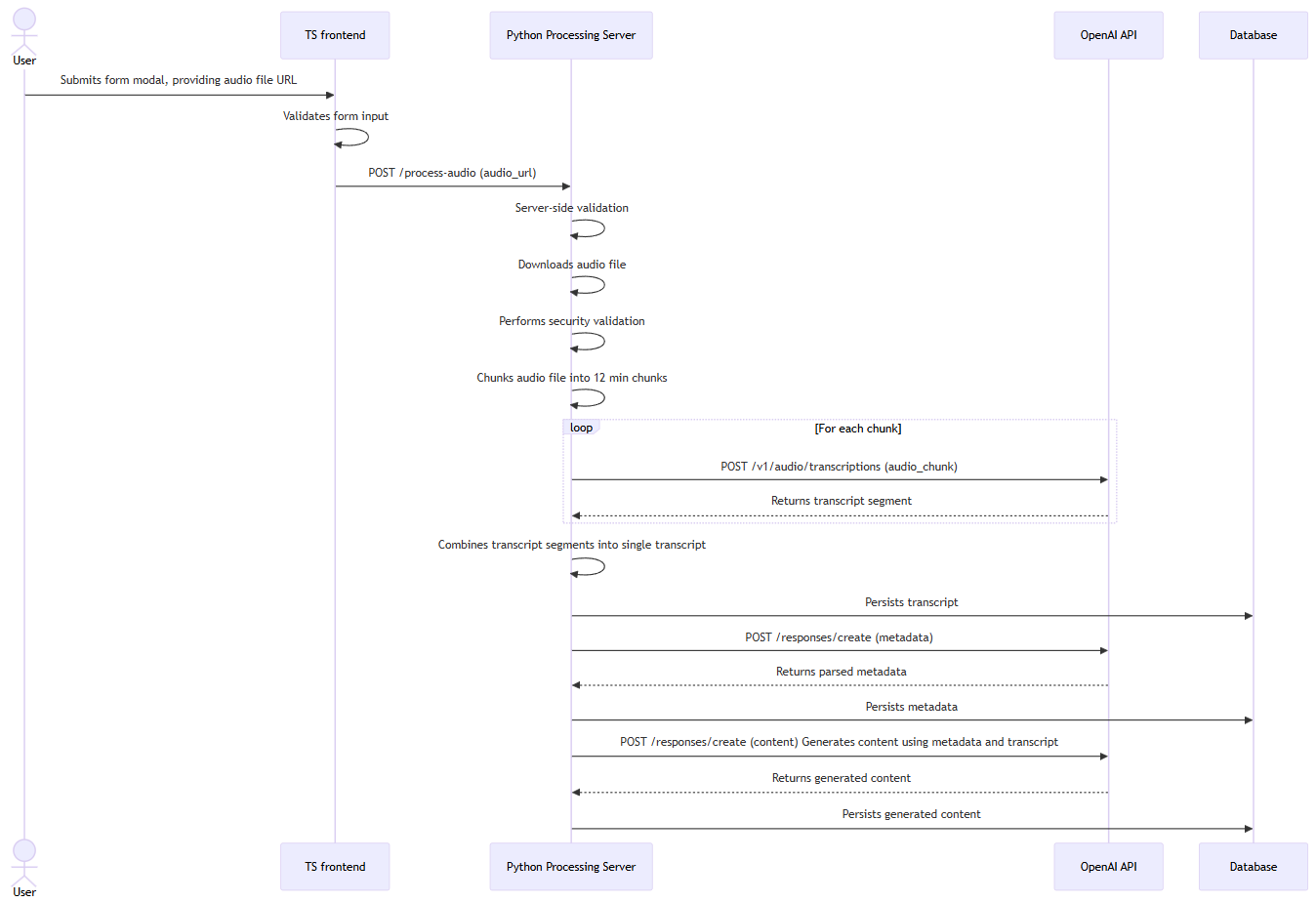 Podscribr.com audio processing sequence diagram
Podscribr.com audio processing sequence diagram
Technical Choices
Selected Python with PyDub for the audio transcription service as recommended by OpenAI’s documentation for chunking audio files.
Moved to a microservice architecture to overcome serverless execution-time limits on Vercel and Netlify. Deployed the frontend on Vercel and the heavy processing Python backend on a Google Cloud VM to enable extended processing times.
Adopted Tanstack Form for unified DX across the frontend, leveraging Zod for both client- and server-side validation. Keeping form schemas in server and client shared files prevented schema divergence between frontend and backend, enabled immediate feedback to improve user experience, and streamlined development with centralized form error handling.
I leveraged shadcn UI components with Tailwind CSS for the frontend, enabling quick development of a consistent and responsive component system.
Challenges and Solutions
- Execution limits on serverless platforms - The transcription process requires up to 10 minutes per hour of audio and I wasn’t going to be able to stay on the serverless platforms I was used to using like Vercel and Netlify because of their execution-time limits. I decided to split the monolith and use a microservice architecture to separate the frontend to stay on Vercel and put the backend on platforms that allowed for longer execution-time.
- Auth - Because of the microservice architecture, the backend server needs authentication from Supabase. The frontend passes authentication and authorization to the Python server securely by extracting the Supabase-generated
cookieheader and implementing an interface on the Python side to parse the Supabase-signed jwt auth token securely. - Cloud debugging - When I started deploying the Python processing server on cloud services, I found that my container crashed immediately when starting processing. After debugging, I realized that my server was attempting to save files to non-existing disk to pass by file name to OpenAI. I refactored my Python functions to handle the downloaded audio files exclusively in memory as
BytesIOobjects and passing that to OpenAI’s transcription API in chunks. - Memory leaks - The Python processing server runs at ~150MB memory usage at the beginning but balloons to ~2.5GB when processing audio files (expected, because it is decompressing mp3 and other large audio files) and successfully processes files but when finished, it does not release all the used memory back to the OS. After processing 1 file, the container sits at ~900MB RAM usage and memory usage creeps up continually from repeated file processing. I plan to implement worker processes to handle those heavy jobs which will fully die and release memory back to the container when finished, resolving the memory leaks.
- Service reliability - The Python server is monolithic and gets stuck sometimes (turn it off and on again fixes) but that’s not an acceptable solution for a monetizable product. I’m currently implementing a message queue with RabbitMq and Celery workers. This will greatly improve reliability by killing stuck worker processes and automatically retrying failed transcription chunks.
- Cloud monitoring and logging - Struggled to get visibility into the cloud-deployed Python server, especially when the server crashed immediately. I added logging not only with the default logger and configurable logging levels but also an Axiom logger for outputting logs to a queryable stream.
Lessons Learned
- Get a wide variety of user feedback throughout product development - Continuous user feedback (even on static frames) is very important for guiding the direction of product development.
- Iterate even before writing code - Wire frames, pencil drawings, and getting user feedback throughout design process takes much less time than building and then rewriting code.
- Reliability is key - Users don’t want to pay for a tool if the infrastructure is unreliable. It’s more important than features.
- Building consistent forms - Tanstack Form made it very easy to build forms for pages and modals with consistent DX usage but different validation layers (client vs server or both).
- Python - My first Python project touched on server frameworks, APIs, type enforcement with Pydantic, message queues, and audio processing with PyDub.
- Resource management in cloud environments - Testing for RAM and CPU usage of the container before deployment is important, along with setting the docker runtime to restart on crash to ensure the server stays up. Specifying memory limits on the Docker runtime ensures Docker kills its processes so it can restart the container and not getting killed by the host instead.
1 2 3 4 5
docker run -d \ --memory 4.5g \ --memory-swap 4.5g \ --restart always \ "podscribr"
- Cloud server deployment - Learned to use server deployments as a stepping stone to serverless and ensure logging and monitoring throughout the process.
- User feedback - Frontend should be as fast as possible to respond to user input no matter how long the server takes to process because of how humans expect changes to be reflected on the client as soon as they are made. It provides confirmation that the user input wasn’t dropped.
- UI component system design - Leveraging the shadcn component library with Tailwind styling made it quick to build consistent visual design and layouts for the app.
- User Experience - Inline form validation errors to provide feedback always (keep space to prevent DOM shift with
 ), loading spinners and skeletons, toast notifications, and accessible design with ARIA attributes combined with visual valid/invalid form state.- Form inputs are marked
aria-invalid=truewhen they fail validation and styles are applied on <Input> components via classNames witharia-invalid:attribute selectors
aria-invalid={field.state.meta.isTouched && !field.state.meta.isValid}aria-errormessage={`error-${field.name}`}className="aria-invalid:ring-destructive/20 dark:aria-invalid:ring-destructive/40 aria-invalid:border-destructive"
- Form inputs are marked
This is the markup for my text input fields used in forms. fieldMeta
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
const TextField = ({label, field, type, required, readOnly}: { label: string; field: any; type?: React.InputHTMLAttributes<HTMLInputElement>["type"]; required?: boolean; readOnly?: boolean }) => {
const fieldMeta = field.state.meta;
const shouldShowErrors =
fieldMeta.isTouched && (!fieldMeta.isValid || fieldMeta.isValidating);
return (
<>
<Input
// literal type to allow hide passwords by type
type={type || "text"}
name={field.name}
className={`rounded-lg bg-white focus-within:outline-2 ${required ? "input-required" : ""} ${readOnly ? "bg-muted text-muted-foreground" : ""}`}
placeholder={label}
value={field.state.value || ""}
onChange={(e) => field.handleChange(e.target.value)}
onBlur={() => field.handleBlur?.()}
required={required || false}
readOnly={readOnly || false}
// assistive tech will set the element to invalid if the element is touched and invalid (from validator)
aria-invalid={fieldMeta.isTouched && !fieldMeta.isValid}
// assistive tech error message is the contents of the element with below id
aria-errormessage={`error-${field.name}`}
/>
{/* show field errors after input */}
<div
className="text-red-500 font-bold text-sm error-message"
id={`error-${field.name}`}
aria-live="polite"
>
{/* non-empty span to prevent DOM shift on error insertion, show errors if they exist */}
<span>
{shouldShowErrors
? fieldMeta.errors.map((err: any, index: number) => (
<p key={index}>{err.message as string}</p>
))
: null}
</span>
</div>
</>
);
};
Future Considerations
- Dynamic metadata extraction - I’d like to allow users to specify what kinds of metadata they are interested in extracting from the podcast audio. Users have told me before that they’d like the AI to provide some sensible defaults and allow them to select from those rather than having to provide metadata to look for from scratch.
- Get back onto serverless - I anticipate squeezing back down onto serverless to save on costs, Cloudflare workers have unlimited execution time on the free tier, which sounds perfect for my use case.
Links
- Podscribr.com
- Supabase database and user authentication
Backend
- Python
- FastAPI Python API framework
- Pydantic strong typing in Python
- Whisper speech to text model
- PyDub Python audio processing
- Docker app container for cloud deployment
- Google Cloud cloud VM provider
- OpenAi AI transcription and content generation
- RabbitMQ message broker
- Celery workers message queue consumers
Frontend
- TypeScript
- Next.js React meta-framework
- Vercel serverless platform
- Tailwind CSS inline component styling
- Tanstack Form React forms library
- MDX componentized static content like the Podscribr quickstart